AI Gateway for LLM Cost Reduction: Boost Efficiency, Cut Costs
The monthly bill just hit your inbox, and it's higher than last quarter. A common scenario for anyone operating AI-powered applications at scale. LLM API consumption scales directly with usage, and without active management, costs quickly become unsustainable. This operational bottleneck diverts engineering resources from product innovation to cost containment.
Many teams first implement simple caching layers to address this. A basic key-value cache might offer some relief but quickly shows its limitations. LLM prompts are rarely identical string-for-string. Slight variations in user input, even for semantically similar queries, bypass a naive cache entirely, leading to cache misses and unnecessary API calls. This is where an AI gateway for LLM cost reduction becomes essential. It provides intelligent infrastructure designed specifically for the nuances of LLM interactions, extending far beyond basic caching.
Consider Sarah, a Staff Engineer at Innovate-Tech, who is building a customer support chatbot. Her initial architecture connected directly to OpenAI's GPT-4. Innovate-Tech’s users frequently ask questions such as "What's my account balance?" or "Can I see my billing history?"
Sarah implemented a simple Redis cache, storing prompt-response pairs. While initially helpful, the cache hit rate plummeted as user queries varied. For example, "My account balance," "Show me my balance," and "What's the current balance on my account?" are semantically identical but syntactically different. Each variation resulted in a new API call. Innovate-Tech’s OpenAI bill still climbed, hovering around $15,000 per month, far exceeding their projections. Sarah spent days attempting to standardize inputs through prompt engineering, a labor-intensive and incomplete solution.
This illustrates the core challenge: LLM inputs are conversational and varied. A simple string match on a cache key is insufficient. A caching mechanism must understand the meaning of the request, not just its exact wording.
An advanced AI gateway integrates semantic caching, which differs fundamentally from a traditional key-value cache. Instead of matching exact strings, semantic caching uses embedding models to convert incoming prompts into numerical vectors. These vectors represent the semantic meaning of the prompt. When a new prompt arrives, its vector is compared against stored vectors of previous prompts. If a sufficiently similar vector (meaning, a semantically similar query) is found within a defined threshold, the gateway serves the cached response.
This intelligent approach significantly increases cache hit rates by accounting for linguistic variations. Sarah’s users asking "My account balance" and "Show me my balance" would now hit the same cached response, significantly reducing redundant API calls.
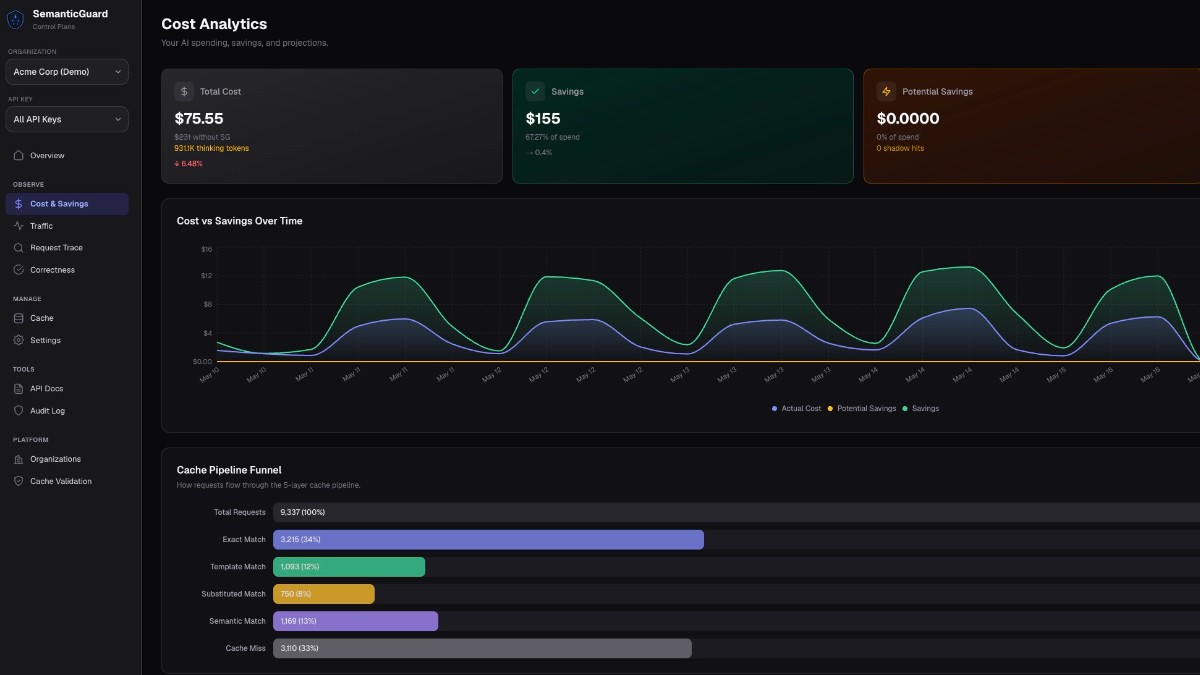
Beyond cost, semantic caching offers tangible performance benefits. According to SemanticGuard's internal benchmark data, cache hits are served locally, typically in under 50ms. This bypasses the latency inherent in making external API calls to remote LLM providers, significantly improving response times, enhancing user experience, and improving scalability.
While semantic caching is a primary driver for cost reduction, a comprehensive AI gateway offers a suite of features that contribute to both efficiency and operational robustness. An AI gateway prevents vendor lock-in by routing requests to multiple LLM providers like OpenAI, Anthropic, or Google AI from a single integration point. This flexibility enables A/B testing of different models and facilitates dynamic routing based on factors such as cost, latency, or model performance.
Furthermore, gateways implement sophisticated rate limiting to prevent individual users or applications from exhausting API quotas, protecting your LLM API keys from abuse and managing traffic effectively. Load balancing across multiple API keys or providers ensures high availability and distributes traffic efficiently. For example, an e-commerce platform could distribute requests to different providers during peak sales to prevent service interruptions and maintain low latency.
Observability and analytics are crucial for optimization, as an AI gateway provides a centralized point for logging all requests and responses. It offers dashboards for monitoring costs, cache hit rates, latency, and error rates. This granular visibility helps identify high-cost prompts or underperforming models, allowing teams to make data-driven decisions. The gateway also acts as a proxy to centralize authentication and authorization for your LLM APIs, enhancing security and compliance. It can be deployed within your own infrastructure, ensuring sensitive data remains within your control and your API keys are managed centrally, reducing exposure.
Finally, a robust gateway features a fail-open design for resilience. If an issue occurs with the gateway itself or an upstream LLM provider, this design ensures your application continues to function by directly routing requests to the LLM provider, maintaining service availability. This prevents your application from going down even if a component in the gateway or a specific LLM provider experiences an outage.
Implementing an AI gateway should not require a complete rewrite of your application. The best solutions offer straightforward integration, often through a simple code change or SDK wrapper. For instance, with SemanticGuard, you can integrate within minutes.
import { withSemanticGuard } from "@semanticguard/ai-sdk";
import OpenAI from "openai"; // Assuming you're using the official OpenAI SDK
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
fetch: withSemanticGuard() // This line routes traffic through the gateway
});
// Now, any call made through this 'openai' client will utilize SemanticGuard's features
async function generateResponse(prompt: string) {
const completion = await openai.chat.completions.create({
model: "gpt-4",
messages: [{ role: "user", content: prompt }],
});
console.log(completion.choices[0].message.content);
}
generateResponse("What's the capital of France?");
This single line of code allows you to transparently route all your existing LLM calls through the gateway. Deploying it directly into your infrastructure, like Vercel, further enhances control and minimizes external dependencies.
A significant hurdle in adopting new infrastructure is justifying the investment and proving its value. Features like 'Shadow Mode' are invaluable here. In Shadow Mode, your application continues to make direct API calls to your LLM provider. Simultaneously, the AI gateway processes those requests in the background, simulating how it would have handled them. It calculates potential cache hits, latency reductions, and critically, the exact cost savings you would have realized.
For Innovate-Tech, Sarah could run SemanticGuard in Shadow Mode for a week. The report would show exactly how many redundant calls were made, how many would have been cached, and precisely how much of that $15,000 monthly bill could have been saved. This data-driven proof, often demonstrating 40-70% cost reductions without any false positives according to SemanticGuard's internal benchmark data, allows engineering teams to make informed decisions. It eliminates guesswork and provides tangible metrics before fully committing to routing production traffic.
The increasing adoption of LLMs in production applications makes managing their operational costs and performance a strategic imperative. Relying solely on direct API calls or rudimentary caching will inevitably lead to inflated bills and potential performance bottlenecks. An advanced AI gateway provides an intelligent layer that optimizes LLM interactions at scale. It offers not just cost savings through semantic caching, but also improved performance, greater control, enhanced security, and crucial observability. Integrating an AI gateway is a foundational component for any organization serious about building scalable, cost-effective, and high-performance LLM applications.