Blog
AI gateway insights, LLM cost optimization, and product updates.
AI gateway insights, LLM cost optimization, and product updates.

Learn how to deploy an LLM semantic cache on Vercel to cut API costs. A practical guide for developers to reduce latency and save on GPT-4 usage.

Learn how semantic caching for the OpenAI API can cut your LLM costs by 40-70%. Implement with one line of code to reduce redundant API calls.
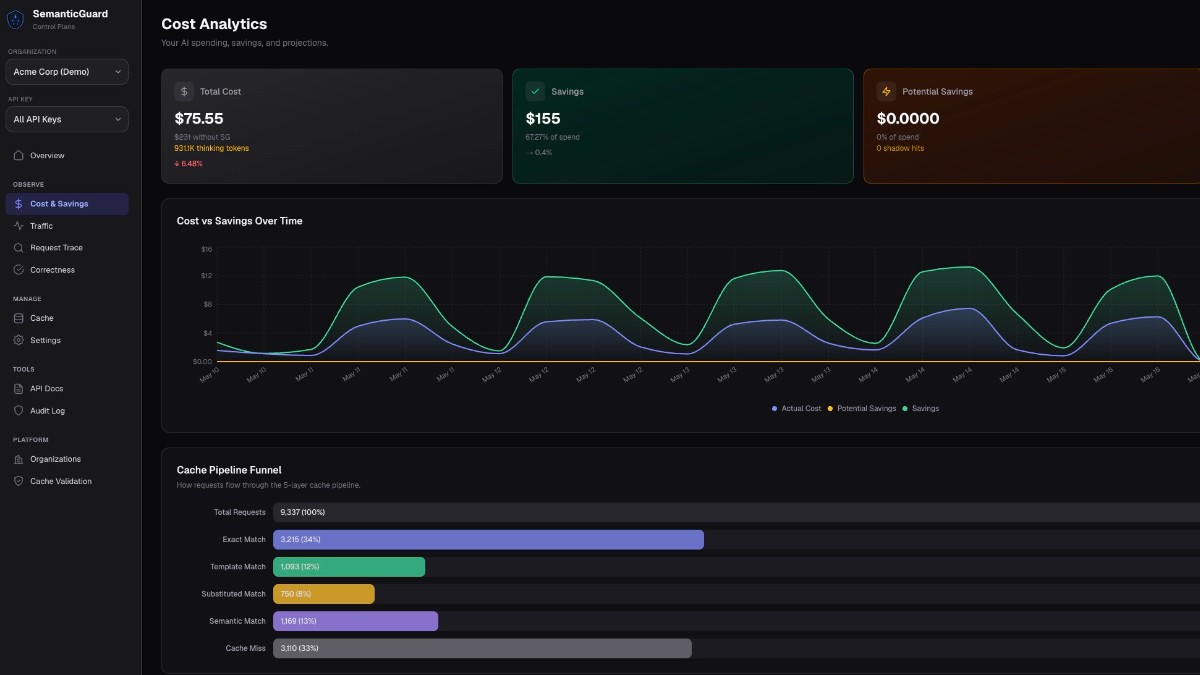
Cut LLM API costs by 40-70% using an AI gateway with intelligent semantic caching. Improve performance, enhance security, and gain full visibility into LLM usage.

SemanticGuard cuts LLM API costs by 40-70% with intelligent semantic caching. One-line integration, zero false positives, under 50ms cache hits.

Learn how a multi-layer validation system combining embeddings with entity recognition eliminates the risk of false positives in LLM semantic caching solutions.

Secure your LLM data with SemanticGuard, a data privacy LLM caching solution deploying directly to your infrastructure. Reduce costs and ensure compliance.

Learn how a semantic gateway with intelligent caching can reduce your Anthropic API costs by 40-70% by eliminating redundant, semantically identical calls.

AWS, Azure, and GCP billing reports lag hours behind your LLM spend. Learn how to track token costs in real-time and stop overpaying on AI API calls.
Learn how to create a robust LLM cost governance framework. This guide covers tracking spend per consumer, setting budgets, and using AI gateways for control.

Learn the difference between a semantic cache and an exact-match cache for LLMs. See how to cut LLM costs by choosing the right caching strategy.